I am a Computer Science Ph.D. student at Stanford University. Here, I work with Shaul. My research focuses on learning how different regions of the human brain in both hemispheres interact during speech in different words, to better identify target areas for Brain-Computer Interfaces (BCIs) implantation.
On a personal level, I have developed research interest in the merge of human cognition with AI through BCIs, where humans themselves become the next platform. So I am currently writing one paper titled As We May Merge: Rise of the Human Platform. I also plan to share my vision on YouTube.
I studied physics (BS, dropout), math (BS), industrial engineering (BS, minor), and computer science (MS). Now I am studying neuroscience (PhD).
Previously, I served in the ROK Army (21 months) and worked at broadcasting company (7 months), nonprofit organization (6 months), consulting firm (3 months), manufacturing company (2 months), big tech (19 months), and IT startup (5 months).
I am open to discussing research ideas, exploring collaborations, offering technical advice, or supporting startups and tech-focused individuals. I am also happy to assist with career guidance, PhD applications, or general advice on graduate life.
100+ past conversations with students, researchers, and founders. → See the full list
Book a chatI am sharing my application materials for those preparing for PhD admissions: 1) Statement of Purpose, 2) Personal Statement, 3) Interview Notes
These days, I practice calisthenics like handstand push-ups. I log my daily life to keep track of life's beautiful moments I may not want to forget. I love connecting with new people. I own more than 400 comic books and enjoy watching films and reading novels and poems. I really love this quote:
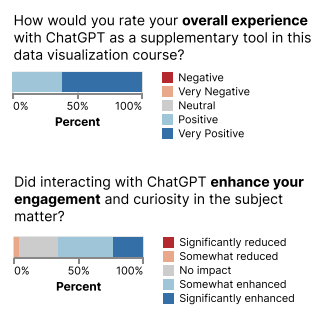
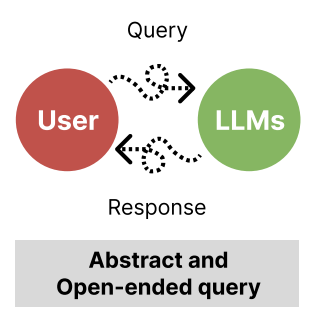
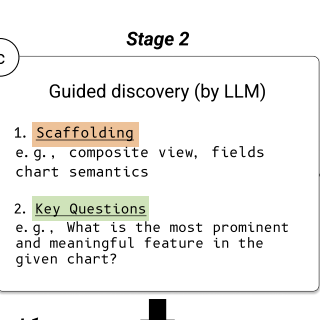
CHI 2024
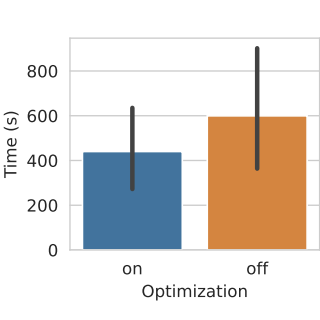


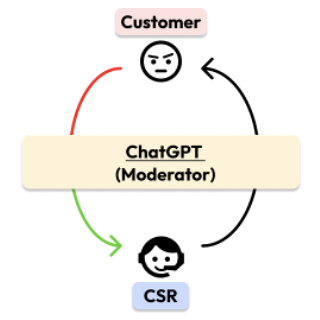
CHI 2023 Generative AI and HCI Workshop
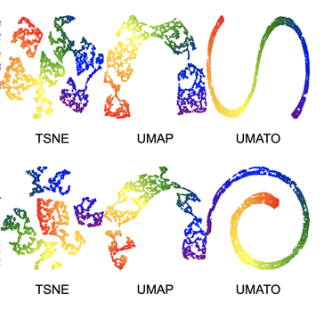





Spring 2026
16-type personality test based on four philosophical and psychological axes of life orientation

Spring 2022
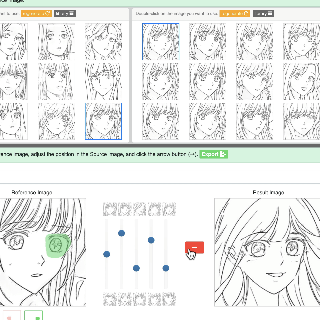
Convert human-drawn abstract sketch image to an anime character with varying styles